
现在你已经成功安装了 Stable Diffusion WebUI (Automatic 1111)(如果还没有,请点击这里查看我们的安装教程),让我们开始生成你的第一张图像吧!
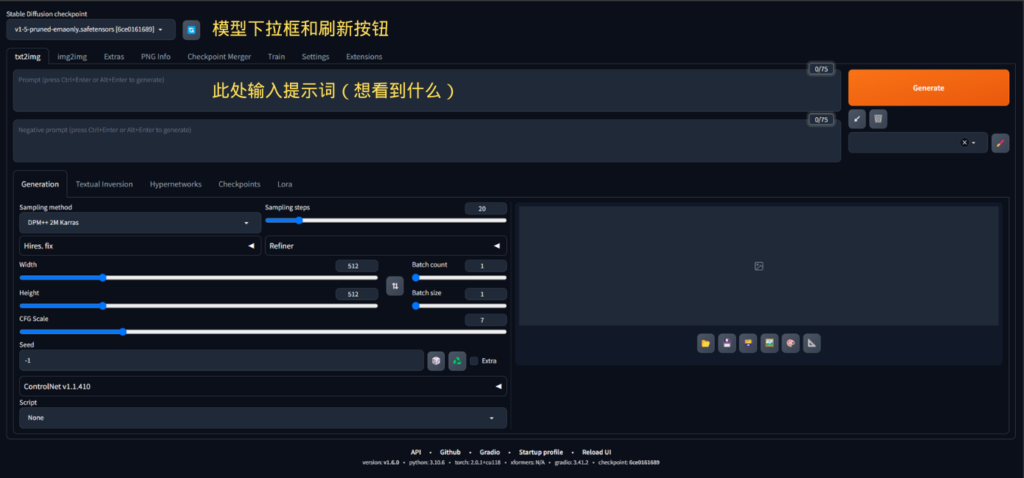
在 sdwebui 文件夹中运行 run.bat,就会出现以下界面(如果你的用户界面看起来不完全一样,也不用担心):
您的第一张图片
- 在生成任何图像之前,请确保您已经安装了模型-请查看左上角 ” Stable Diffusion checkpoint”文字下的下拉字段,如果可以看到名为 “v1.5 pruned emaonly safetensors “的模型,则说明您已经安装了 SD1.5 基本模型。 如果该字段为空,则需要下载并安装该基本模型。 最简单的方法是访问 https://stable-diffusion-art.com/models/#Stable_diffusion_v15 并单击下载链接。 这将下载 v1-5-pruned-emaonly.ckpt 文件,您应将其放在 …\sdwebui\webui\models\Stable-diffusion文件夹下,然后点击旁边的蓝色按钮刷新下拉字段。
- 在提示窗口中输入文字,描述您希望 SDWebUI 生成的内容。 可以是一句话,也可以是一系列关键词。
- 点击右上角橙色的 “生成 “按钮,就可以了! 您将看到第一张人工智能生成的图片。
开始实验
生成完一打猫狗图片之后,您就可以开始尝试使用界面的其他功能和控制了,但是界面上有太多的菜单和设置了! 我们建议从这里开始:
- 访问 civitai.com,查看其他人正在使用的型号和提示。 对于模型,您会在每个缩略图的左上角看到 “Checkpoint”、”Checkpoint XL “或 “Lora”。 您还可以筛选不同类型的模型(例如,有些模型侧重于照片写实,而另一些则用于动漫)。 Dreamshaper 和 Realistic Vision 5.1 是排名靠前的模型,在尝试其他模型之前,它们会给你带来很多创作的乐趣。 除非你有强大的显卡,否则请使用 SD1.5(及其衍生模型),避免使用 SDXL(根据 stability.ai,SDXL 需要 Nvidia GeForce RTX 20 或更高显卡,至少 8GB VRAM,以及 Win 10/11 和 16GB 内存)。
- 创意人员每分钟都在生成令人惊叹的图像-点击显示图像右下角带 “i “的小圆圈,就能看到生成该图像所使用的参数(提示/负提示、模型等)。 将这些参数复制到自己的 SDWebUI 中进行测试。 请注意,即使您使用了相同的提示、模型、种子和其他参数,也不可能得到完全相同的输出结果-不同的显卡会产生不同的结果,原作者也可能应用了额外的工作流程步骤。 不过,通过观察他人的作品,您可以学到很多关于如何有效使用参数的知识。
- 一些补充提示
- Sampling steps采样步长通常为 20~30 步即可。
- Default resolution默认分辨率为 512×512,可根据您的 VRAM 大小提高分辨率(您会在 Windows 命令窗口中看到内存不足的错误信息)。 提高分辨率也会降低生成速度。
- CFG Scale会影响人工智能与您的提示的紧密程度。 数值通常在 5~9 之间即可。
- Seed种子值为”-1 “表示随机值,如果您喜欢某个生成结果,并希望以后的生成都沿用这种风格,可单击种子下拉列表(和骰子图标)右侧的绿色图标锁定该特定种子。 之后,您可以点击骰子图标重置为-1。
- 通过点击 SDWebUI 中生成图像下方的文件夹图标,您可以看到按日期排列的所有已创建图像。 这是一个方便的工具,可以避免意外丢失已生成的图像,但会占用磁盘空间并可能影响隐私。
下一步,我们建议学习怎样写更好的提示词、扩展程序、img2img、Lora 和 ControlNet。 更全面的指南请访问 https://stable-diffusion-art.com/automatic1111/ 。提示词教程强烈建议https://openart.ai/promptbook。